

Share this tool:
Description:
- Introduction
- Strong Features and Capabilities
- What Resemble AI Actually Does Best
- Where the Workflow Feels Strongest
- Voice Quality, Control, and Model Layers That Matter
- Detection, Identity, and Deepfake Defense
- Where Resemble AI Is Strongest in Real Use
- Quick Comparison
- Practical Tips
- Limitations and Trade-Offs
- Final Takeaway
Resemble AI is a programmable voice platform for text-to-speech, cloning, speech-to-speech, transcription, and agents, plus a security stack for watermarking, identity verification, and multimodal deepfake detection across audio, image, video, and even live meetings. That combination is what makes it interesting, and it is also what makes it slightly harder to evaluate than a simpler “AI voice generator” app.
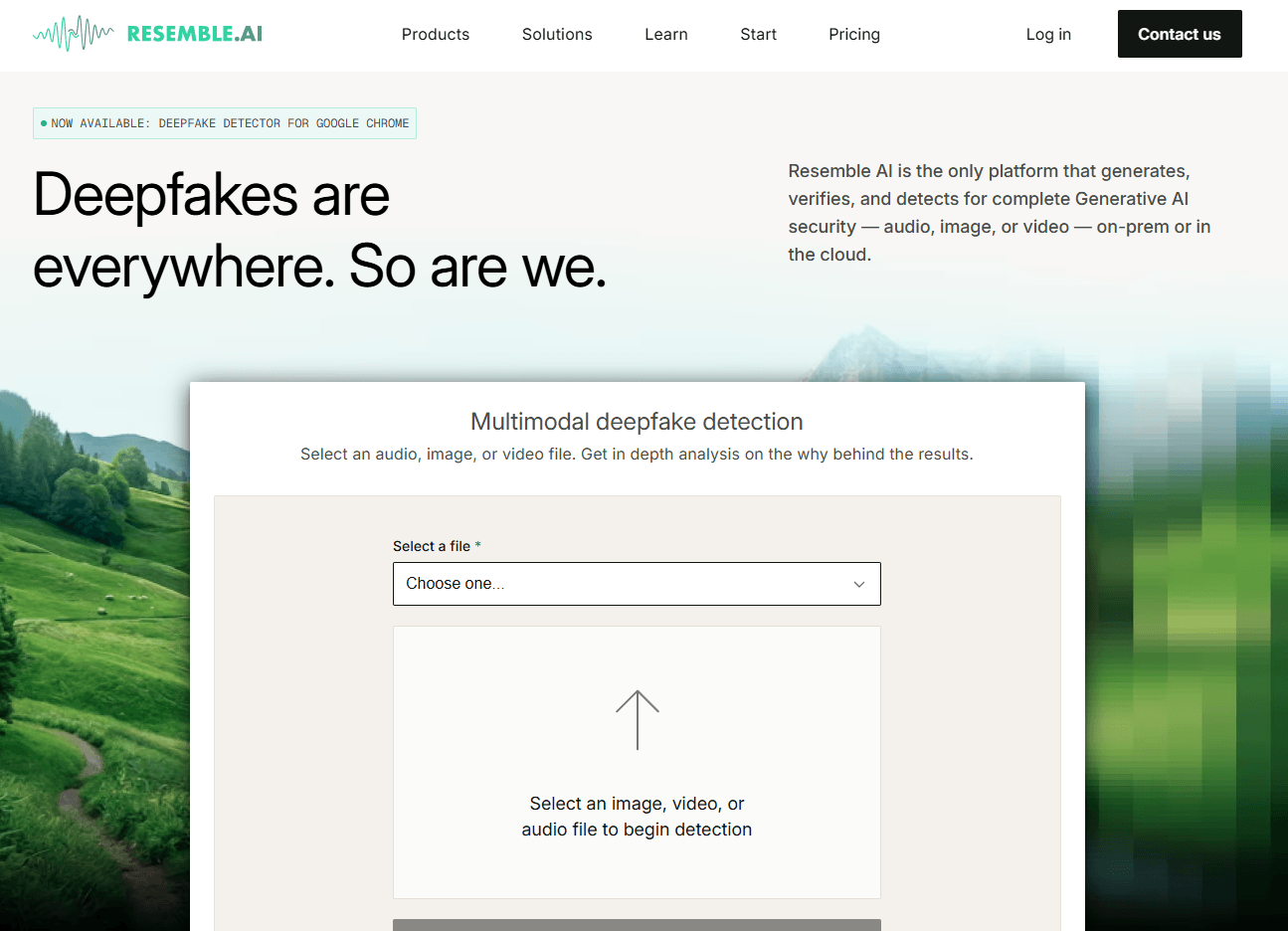
Resemble’s TTS product advertises natural speech in 100 languages, sub-200ms latency, custom pronunciation support, and cloud, on-prem, or air-gapped deployment options.
You can use Rapid Clone from about 10 seconds of audio, Professional Clone from 10 to 25+ minutes, or Voice Design to generate voice candidates from a text description.
The platform covers speech-to-speech, transcript-based audio editing, speech-to-text with follow-up intelligence queries, and enhancement for noise removal, normalization, and studio-style cleanup.
Resemble’s agents combine ASR, TTS, LLMs, and turn-taking, and can be connected to a knowledge base or phone numbers through Twilio-backed telephony.
Resemble Detect, Watermarker, and Identity give the platform a security angle most voice tools do not have, including multimodal detection, audio watermarking, and speaker identity search.
Resemble Meetings extends that detection layer into Zoom, Teams, Google Meet, and Webex with a bot that can flag synthetic media during calls.
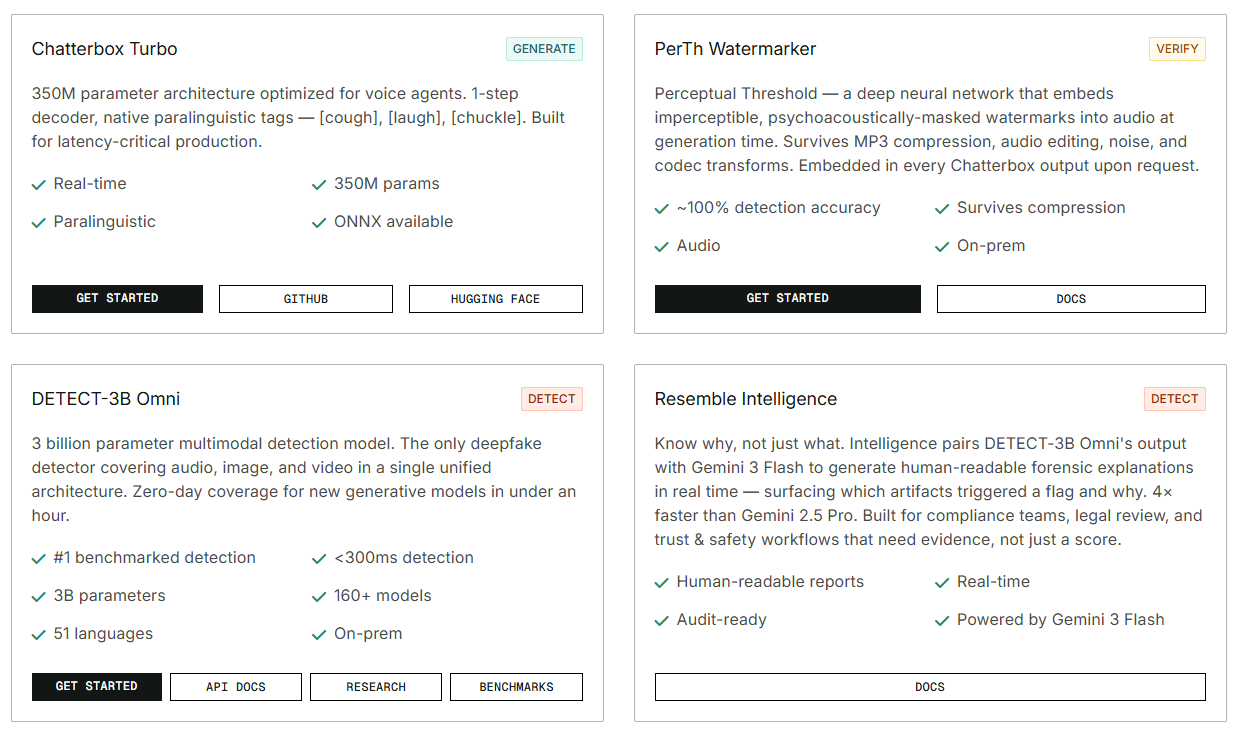
The clearest reason to choose Resemble AI is not that it has the single best voice generator UI. It is that Resemble treats voice as infrastructure, not as a one-off content toy. You can generate speech, create voices, edit and enhance audio, run real-time agents, and then verify or detect synthetic media inside the same overall ecosystem. For teams building call flows, branded voice systems, compliance-heavy media pipelines, or fraud-sensitive workflows, that unified shape is more valuable than a prettier “type text, get mp3” experience.
That unified shape matters even more because the product now spans three distinct jobs. First, there is voice generation: TTS, cloning, voice design, speech-to-speech, and editing. Second, there is interaction infrastructure: streaming, agents, knowledge bases, and phone integration. Third, there is safety and trust: deepfake detection, identity matching, watermarking, and meeting protection. Most competitors cover one or two of those jobs. Resemble is trying to cover all three.
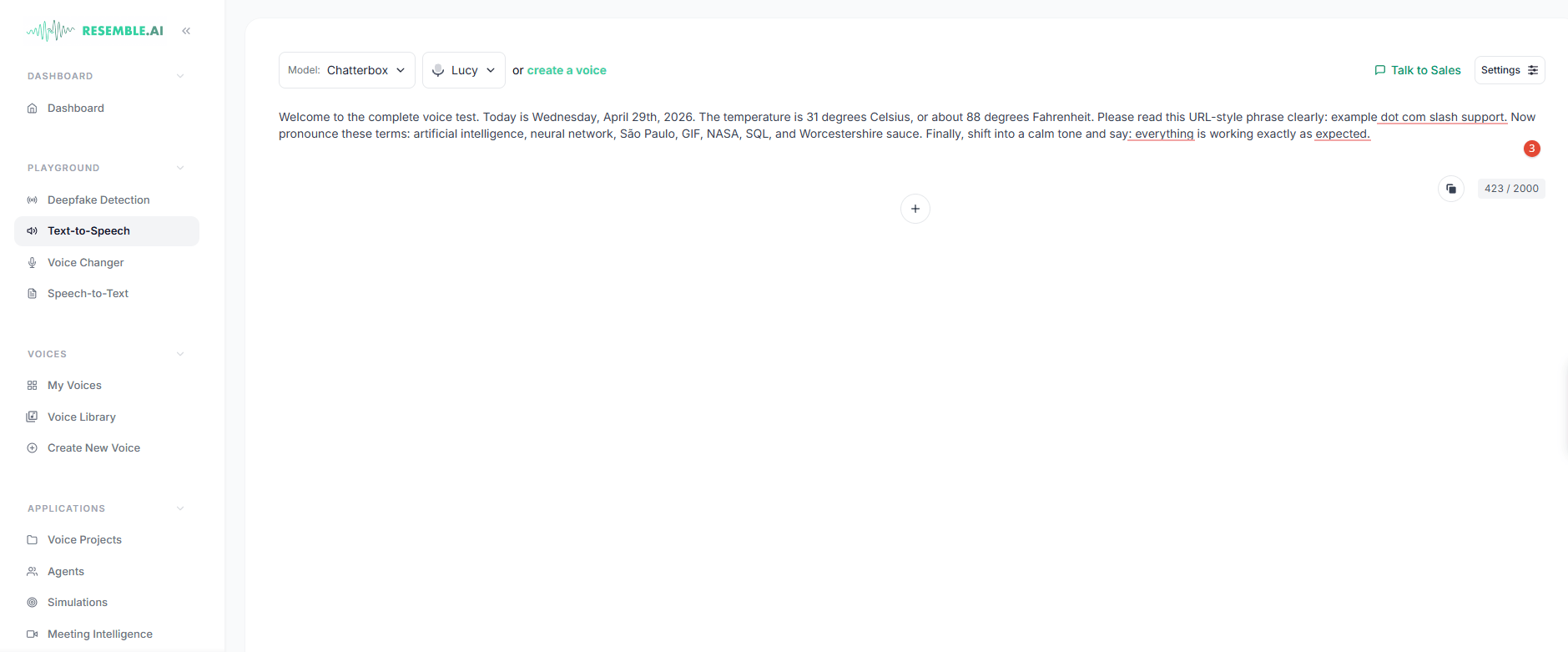
For developers, the workflow is relatively clear. The docs are organized around concrete API lanes: text-to-speech, speech-to-speech, voice cloning, voice design, speech-to-text, audio edit, audio enhancement, agents, and detection. There are official Node.js and Python SDKs, plus both synchronous and streaming TTS options, including HTTP streaming and a WebSocket path for lower-latency real-time applications.
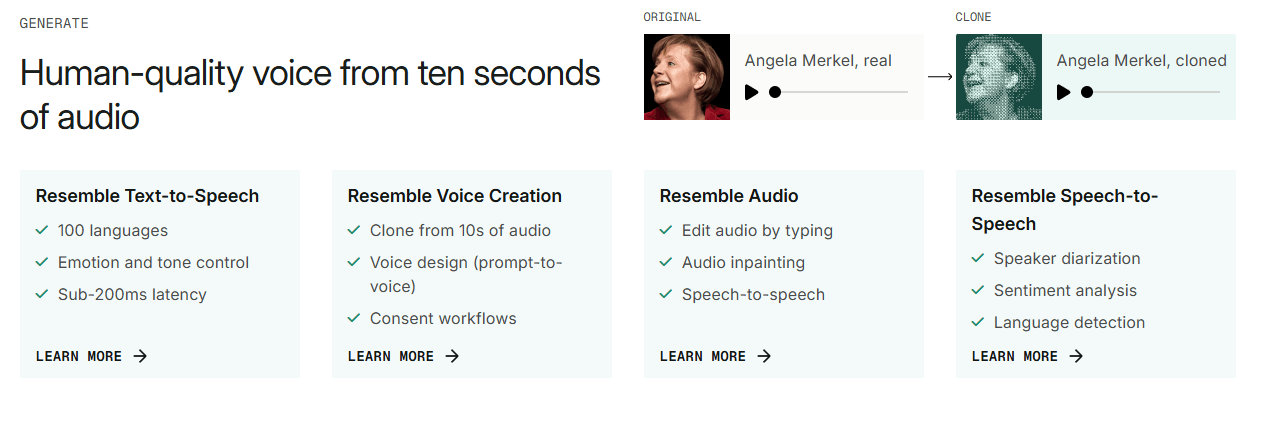
The voice creation side is also sensibly split. Rapid Clone is the fast path when you need a functional voice quickly; Professional Clone is the slower path when fidelity matters more. The docs frame Rapid as a quick-iteration option from 10 seconds to 3 minutes of audio, while Professional uses 10 to 25+ minutes and is aimed at more production-grade work such as audiobooks, podcasts, and video games. Voice Design then gives you a third route: describe the voice you want in text and Resemble returns three voice candidates to choose from.
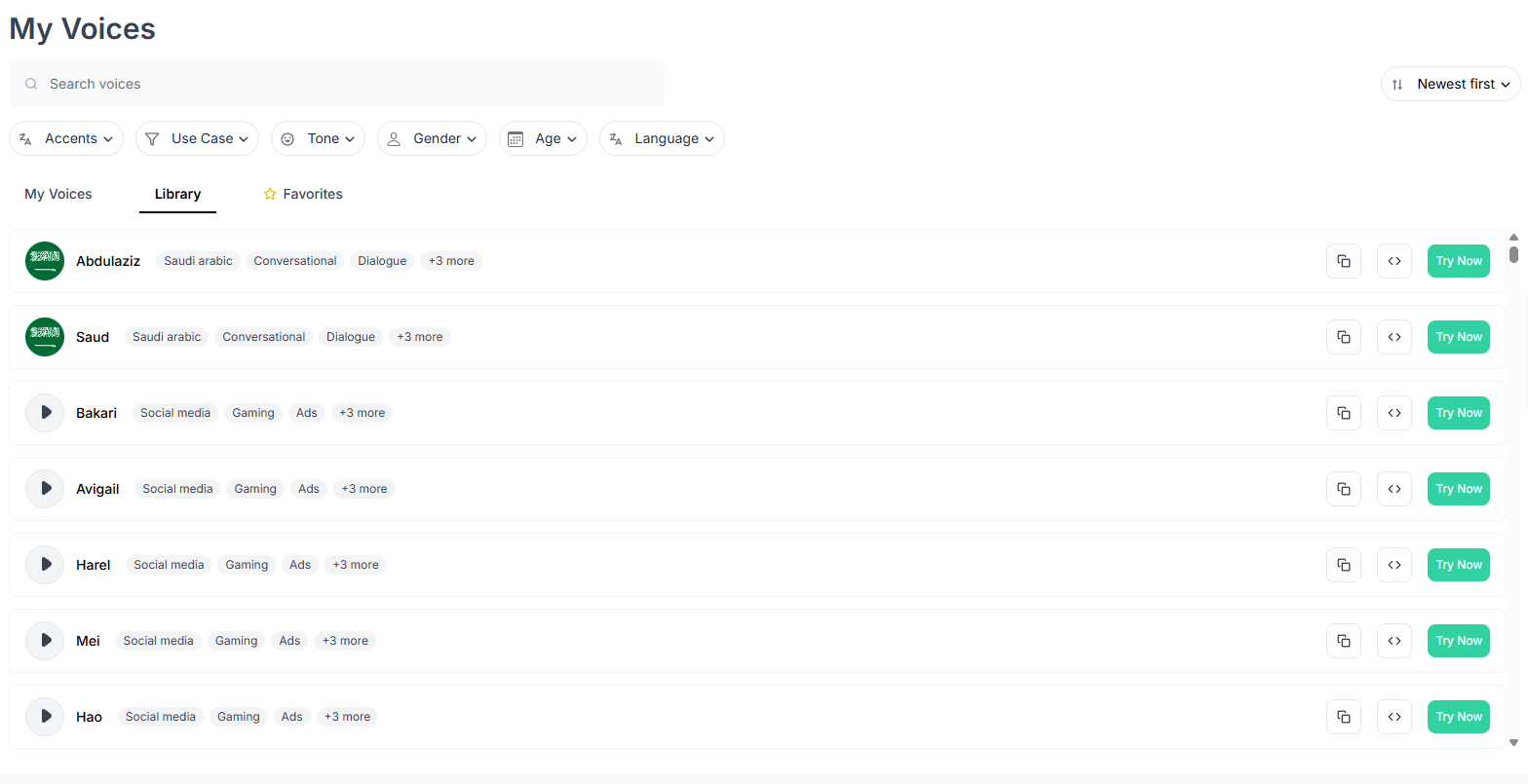
The audio tools are practical in a very API-first way. Speech-to-speech preserves the donor recording’s timing and delivery while converting it into a target voice. Audio Edit lets you change spoken content by providing the original transcript, target transcript, a voice, and the input audio. Audio Enhancement is asynchronous and focused on cleanup rather than creativity: noise removal, normalization, and studio-style polish. Speech-to-text returns speaker labels and word-level timestamps, and then lets you ask follow-up intelligence questions against the transcript.
That last point is important: Resemble is strongest when you think in workflows, not isolated generations. The product is built around “submit, poll, retrieve, then continue processing,” which is excellent for systems and pipelines but less charming for casual creators who want a polished desktop-style production studio.
The model story is meaningful here. On the generation side, the key family is Chatterbox. Resemble positions it as the backbone for hosted TTS and voice creation, while also offering an MIT-licensed open-source version with emotion control, zero-shot voice cloning, real-time generation, and built-in PerTh watermarking. The hosted product page emphasizes 100 languages for TTS, but the cloning and open-source pages repeatedly emphasize 23 or 23+ languages for multilingual cloning. In practice, that means the broad TTS language headline is not the same thing as full cloned-voice language coverage.
Control is another strong point. Resemble supports custom pronunciations through reference audio, and those pronunciations can be applied automatically during synthesis. Speech-to-speech also accepts prompting to adjust accent, tone, or speaking style while preserving timing and prosody. That combination makes Resemble feel more production-oriented than basic TTS tools that mostly stop at “choose voice, choose speed.”
On the security side, the important model name is DETECT-3B Omni. Resemble says it powers multimodal deepfake detection across audio, video, and images, and that Detect returns not just a score but a verdict, explanation, and chain of custody. The adjacent Identity product is powered by Resemblyzer for speaker enrollment and matching, and Watermarker adds provenance tooling on top, although the Watermark API is still marked beta in the docs.
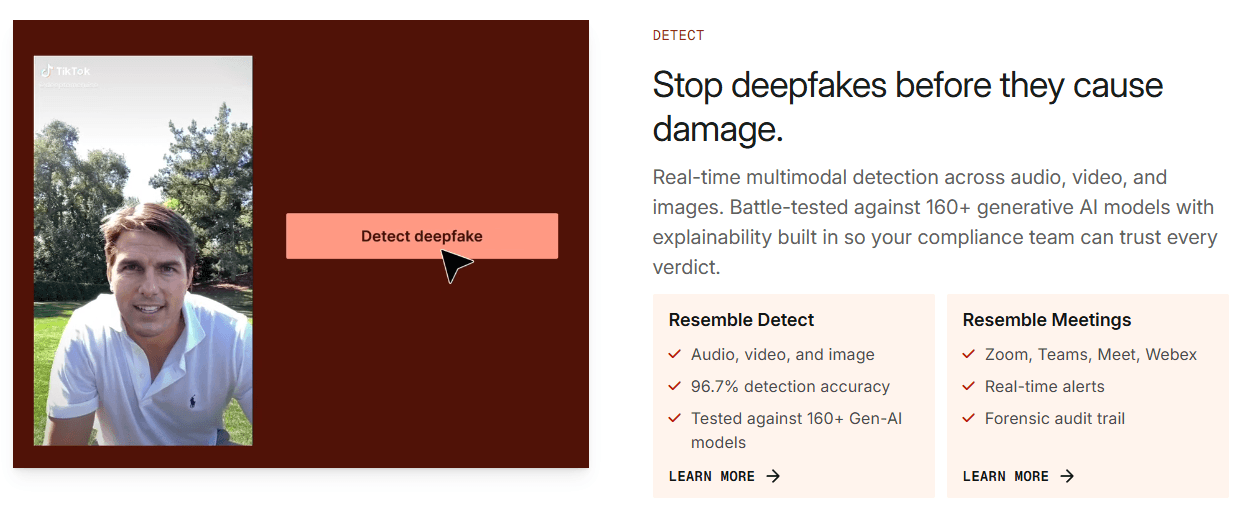
This security layer is the biggest reason Resemble AI feels different from more creator-focused voice platforms. The product is not only about generating convincing voices. It is also about proving, checking, and defending voice authenticity in environments where synthetic media can create real operational risk.
Resemble AI makes the most sense for five kinds of buyers.
- Voice-agent teams: The platform supports TTS, ASR, LLM-backed agents, turn-taking, phone numbers, Twilio integration, and knowledge bases that can ingest documents, URLs, and text for RAG-style responses.
- Secure branded voice deployment: If you want a cloned or designed voice that can be used across products, with watermarking and provenance in the conversation from the start, Resemble has a more enterprise-minded posture than many creator-first voice tools.
- Localization and audio revision: Speech-to-speech, audio edit, and enhancement are exactly the sort of tools you want when the job is “keep the delivery, fix the words, clean the file, reuse the voice.”
- Fraud, compliance, and trust workflows: Resemble Detect, Identity, Watermarker, and Meetings clearly target financial services, public sector, telecom, legal, and other environments where proving authenticity matters as much as generation quality.
- Developers who want APIs and deployment flexibility: Resemble supports cloud, on-prem, and air-gapped deployment across parts of the platform, offers SDKs, exposes rate limits and concurrency details in docs, and keeps the product centered on programmable workflows.
Compared with ElevenLabs, Resemble AI is more security-heavy and infrastructure-oriented. ElevenLabs also offers a broad API and web stack for TTS, STT, cloning, conversational agents, and generative audio, plus 70+ language support on its main voice platform. But ElevenLabs is still more naturally framed as a voice generation company, while Resemble’s clearest differentiator is that it combines generation with provenance, identity, and deepfake defense in the same platform.
Compared with Pindrop, Resemble is broader and more builder-friendly because it includes voice generation and media tooling in addition to detection. Pindrop is more tightly focused on fraud defense, contact centers, and deepfake detection in security-sensitive environments. So if your problem is mainly “secure the call center,” Pindrop is a more direct specialist. If your problem is “build voice systems and secure them too,” Resemble is the more complete fit.
- Use Rapid Clone for testing, demos, and early product work, then move to Professional Clone when the voice is client-facing or central to the experience. That is exactly how Resemble’s own docs position the trade-off.
- Use speech-to-speech when the performance already exists and you want to preserve timing and delivery. Use plain TTS when you are generating fresh speech from scratch. Resemble separates those workflows clearly, and they solve different problems.
- Use custom pronunciations early if names, product terms, or regulated terminology matter. It is easier to fix pronunciation at the platform layer than to keep repairing bad generations downstream.
- If you are building live agents, check the streaming path you actually need. HTTP streaming is public, but the lower-latency WebSocket API is currently documented as Business plan and above.
- If security matters, ask about deployment mode, retention, and feature maturity up front. Resemble advertises on-prem, air-gapped, and zero-retention options on parts of the platform, but the Watermark API is still in beta, so not every trust feature is equally mature.
- The biggest limitation is complexity. Resemble AI is not one simple voice app anymore. It is a platform with multiple product lines, multiple models, several asynchronous workflows, separate security layers, and enterprise deployment options. That depth is great for serious teams, but it is more than many solo creators need.
- The second limitation is that the product can feel a little uneven depending on which lane you are in. Some parts are polished marketing surfaces, while other parts are very API-first and operational. Audio Edit, for example, requires an owned non-marketplace voice and works as an asynchronous job. That is powerful, but it is not the same as sitting in a friendly timeline editor and dragging clips around.
- The third limitation is access clarity. The site is current overall, but there are a few spots where plan requirements or capability boundaries need double-checking, especially around cloning access and the difference between broad TTS language claims and multilingual cloned-voice coverage. Buyers should verify specifics rather than assume every headline applies equally to every workflow.
- And finally, if you only want a straightforward voiceover generator with a big creator-friendly library and minimal setup, Resemble may be overkill. Its real value appears when you need programmable control, security, provenance, or system-level voice workflows.
Resemble AI is one of the more interesting voice platforms right now because it does not stop at generation. It gives you text-to-speech, cloning, voice design, speech-to-speech, transcript-aware audio tools, agents, identity search, watermarking, and deepfake detection under one roof.
It is best for developers, product teams, security-conscious enterprises, and anyone building voice systems that have to be controlled, auditable, and defensible. The main caveat is that the platform is broader than it is simple, so it is most worth using when you need more than just a nice synthetic voice.
TAGS: Text to Speech
Related Tools:

Provides automated dubbing and translation

Generates audio content from spoken words

Delivers real-time, hyper-realistic voice generation

Open-source office suite for document creation

Transforms texts to natural-sounding speech

Collaborative document editing and project management tool