

Share this tool:
Description:
Speechlab is a localization platform built around two related products: Speechlab Dubbing for prerecorded video and audio, and Speechlab Live for real-time interpretation in webinars, meetings, and broadcasts. The official site positions the platform around speech translation at scale, with an advanced dubbing editor, voice-preserved output across languages, API integrations, team workflows, and optional human review for higher-stakes content.
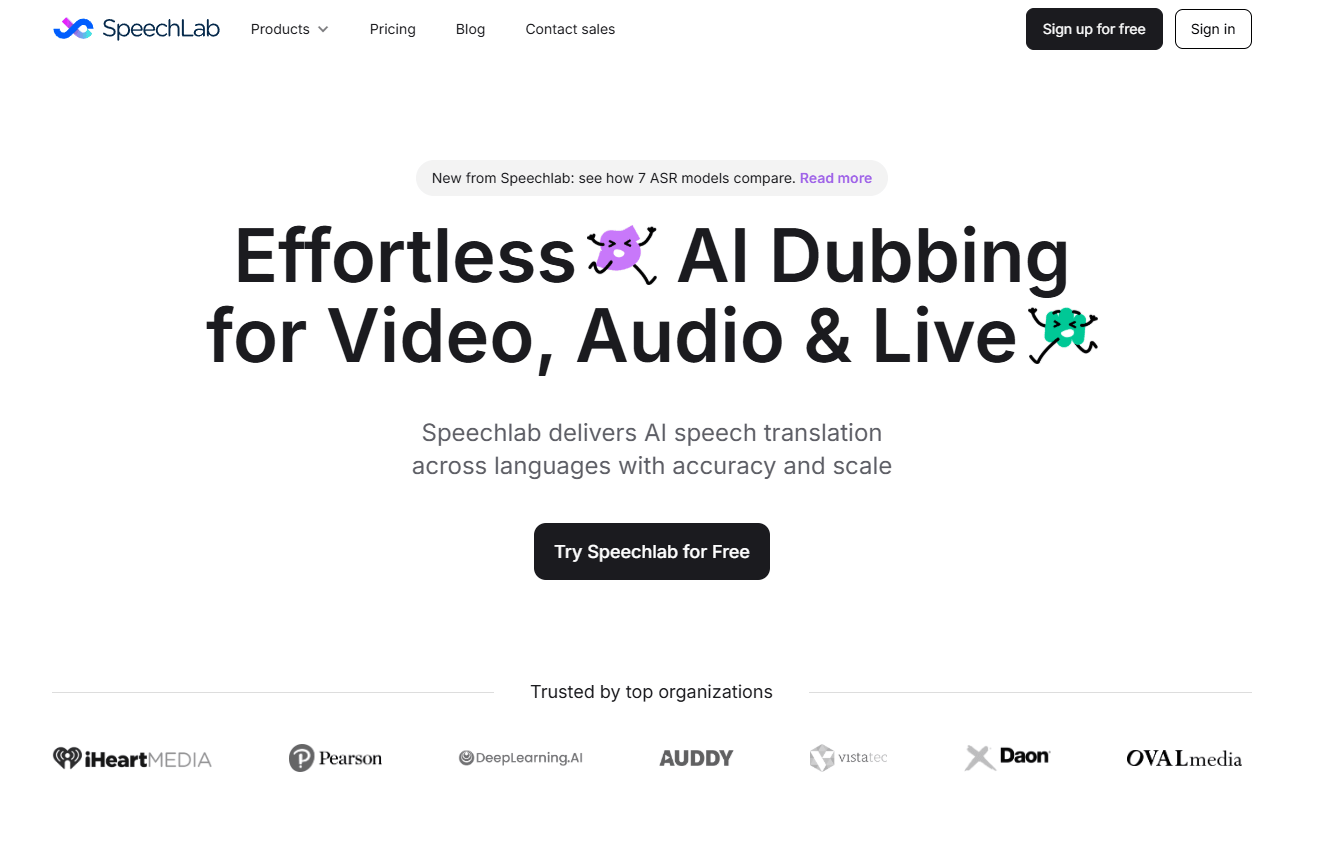
Speechlab combines transcription, translation, and dubbed speech generation in one platform instead of forcing users across separate tools.
The platform’s editor lets teams adjust audio granularly and keep transcript and translation edits in sync with the dub.
Speechlab supports both original-sounding voice output and native speaker matching, rather than locking users into a single voice approach.
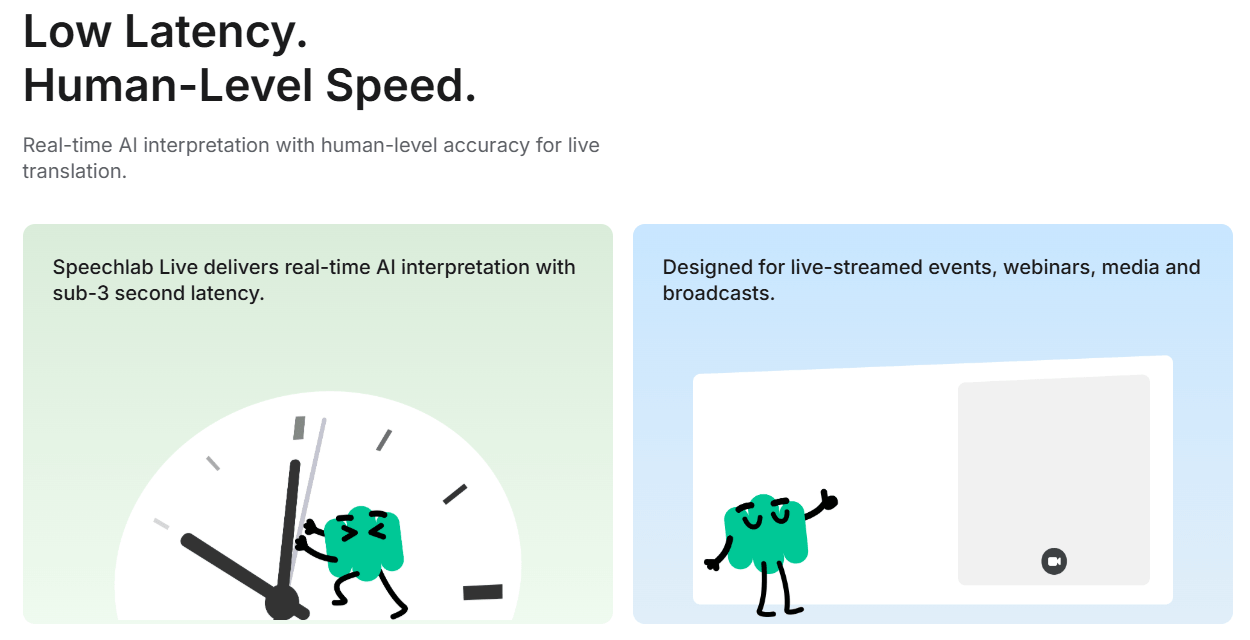
Speechlab Live adds sub-3-second AI interpretation for events, webinars, and media workflows, with Zoom, Google Meet, and Teams integration.
The public site highlights collaboration, bulk processing, APIs, role-based access, and linguist-reviewed outputs for larger teams.
Speechlab says it processes thousands of hours of audio every week and benchmarks ASR models on real production audio to decide what runs in its pipeline.
Speechlab is strongest when you already have content and need to localize it in a way that still feels production-aware. The product is clearly built for dubbing existing video and audio libraries, not for novelty voice generation. Its homepage emphasizes transcribe, translate, and dub synthesis in one workflow, while its blog repeatedly frames the value around timing alignment, background-audio handling, speaker labeling, transcript review, and human review layers where needed. That is a much more useful shape for publishers, educators, marketers, and media teams than a basic “type text, get voice” tool.
That focus matters because dubbing quality is rarely limited by speech synthesis alone. The hard parts are usually upstream and downstream: separating vocals from background audio, segmenting speech in the right places, keeping meaning intact through translation, preserving timing, and making the final result editable when something sounds wrong. Speechlab’s own explanation of automated dubbing leans heavily on exactly those problems, which is a good sign that the company is solving the workflow rather than only advertising a voice model.
The cleanest way to understand Speechlab is to split it into two layers.
This is the prerecorded-content side: AI dubbing with advanced language processing, voice-preserved output, granular editing, collaboration, and enterprise localization workflows.
This is the real-time side: multilingual interpretation for events, webinars, and broadcasts with direct use in Zoom, Google Meet, Microsoft Teams, or custom AV setups.
That two-layer setup is one of the product’s clearest strengths. Some buyers need prerecorded localization for a library of content. Others need real-time interpretation on top of existing meeting or broadcast workflows. Speechlab is more interesting than many voice tools because those two needs sit under one brand and a broadly similar “speech translation at scale” positioning.
The editor looks like one of Speechlab’s most important practical differentiators. The homepage says the advanced editor allows granular audio adjustment while keeping edited transcripts and translations in sync. The March 2026 workflow article expands on that by describing a dubbing-editor model where source content is segmented by meaning, translated with full context, reviewed at the segment level, and then used to generate both dubbed audio and subtitles from a shared source of truth.
That “single workflow for dubbing and captions” idea is more valuable than it first sounds. Speechlab argues that many teams still run captions and dubbing as separate processes, which creates mismatches between subtitle files and dubbed audio. Their answer is to start from meaning-based segments rather than caption card fragments, then derive both deliverables from the same reviewed translation. Whether or not you buy every bit of the company’s argument, the workflow itself is sensible: one translation pass, one review pass, multiple outputs.
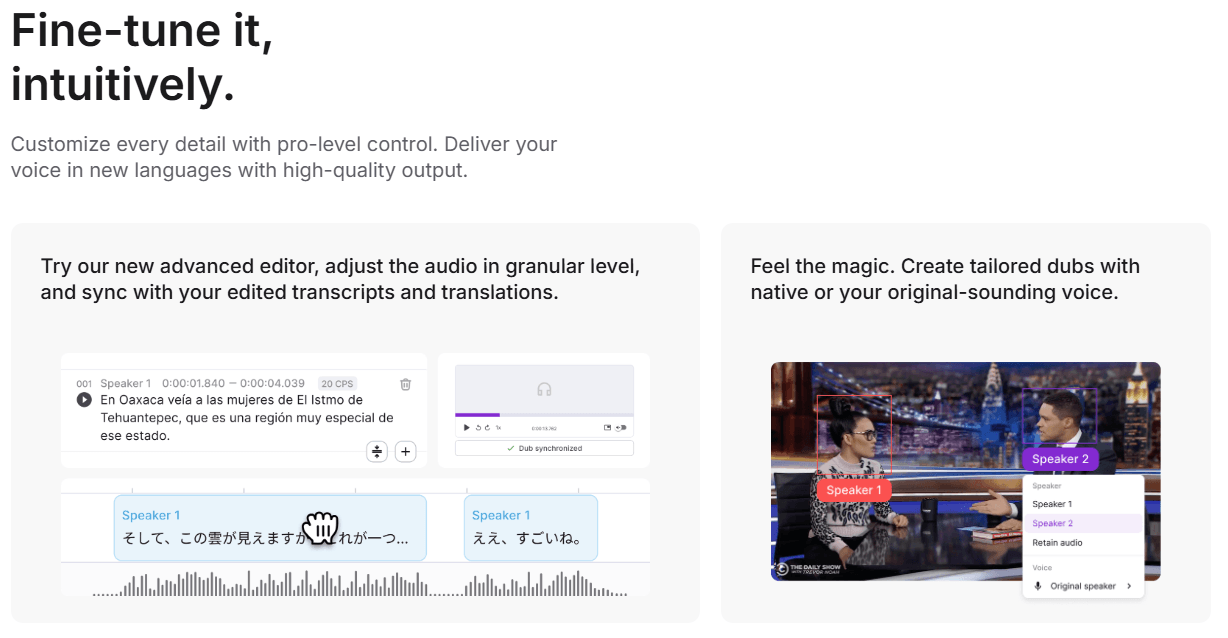
The platform also appears built for partial revision rather than all-or-nothing reruns. Speechlab’s April 2026 enterprise guide explicitly treats transcript-level editing and targeted re-dubbing as important evaluation criteria, especially for content libraries that change over time. That is exactly the kind of detail that matters in real production. A tool that can localize one video is useful. A tool that can re-localize only the changed segments when messaging updates is much more useful.
Speechlab’s voice strategy is more nuanced than many dubbing platforms. The company does support original-sounding dubbed output, but one of its more interesting public positions is that cloning the original speaker is not always the best answer. In January 2024, Speechlab introduced native speaker matching, which uses a rights-cleared database of native voices and automatically pairs source speakers with target-language voices that share similar vocal characteristics. The goal is not exact mimicry. It is natural delivery that still feels aligned with the original speaker.
That is actually a useful distinction. In some content, especially branded spokesperson material, a voice clone may be the right choice because the speaker’s identity matters. In other content, especially longer narratives or more formal localization work, a strong native-language match may sound more natural and avoid the awkwardness of a visibly foreign accent in the dubbed language. Speechlab’s own materials are pretty explicit about this trade-off, and they present having both options in one workflow as a core advantage.
The company’s AI ethics page also makes its position here fairly clear. For voiceover, users must attest that they have the rights and permissions to use any voice sample they provide. For dubbing, Speechlab says its systems are designed to avoid closely mimicking real people without consent, and that customers must confirm they have the rights to produce dubbed versions of the content they upload. That is not just policy boilerplate. It shapes how the product thinks about “voice-preserved” dubbing versus unrestricted impersonation.
Speechlab’s public site and blog are very clearly aimed at professional use cases rather than casual experimentation. The homepage stresses collaboration, universal file support, APIs, bulk processing, role-based access, and human-reviewed enterprise outputs. The company also names customers and partners such as iHeartMedia, Pearson, Deeplearning.ai, Vistatec, Auddy, and Daon, which reinforces the impression that the product is designed for serious content operations.
The company’s own engineering content adds to that. In April 2026, Speechlab published an ASR benchmark based on 9.6 hours of real production audio and said it processes thousands of hours of audio every week across 25+ languages. More importantly, the write-up shows the team cares about pipeline reliability issues that matter in dubbing, including chunk drops, missed speech, boundary precision, and the need for forced alignment rather than only headline transcription accuracy. That makes Speechlab look more operationally mature than platforms that treat dubbing as a thin layer over generic speech models.
Speechlab is a strong fit for publishers and media companies with audio or video libraries that need multilingual distribution. The company’s own materials repeatedly mention podcasts, interviews, documentaries, webinars, and broadcasts, and the workflow emphasis on speaker handling, timing, and background-audio retention fits those formats well.
It also looks well suited to enterprise marketing, sales, and product video localization. Speechlab’s April 2026 guide specifically calls out product demos, onboarding videos, explainer videos, sales presentations, and event recordings as content types where AI dubbing is viable, especially when paired with the right review tier.
Another strong fit is e-learning and training content, especially when teams need repeatable workflows and change management. Transcript-level editing, shared translation sources for both subtitles and dubbed audio, and support for partial re-dubbing all matter more in training libraries than in one-off video experiments.
And finally, Speechlab is a plausible fit for live multilingual events and webinar operations. Speechlab Live’s public positioning is clear: sub-3-second interpretation, 60+ languages, and integration with Zoom, Google Meet, Teams, or custom AV setups. That is a very different job from prerecorded dubbing, but it sits naturally inside the same broader translation stack.
- Use Speechlab when you care about the workflow around the dub, not just the voice itself. The company’s own materials make it clear that the product’s advantage is its integrated pipeline: source separation, speaker labeling, translation, editing, timing, and background-audio reintegration. If all you need is a quick synthetic narrator, this is broader than necessary.
- Use native speaker matching and voice-preserved dubbing differently. Speechlab’s public guidance implies that native matching is often the better choice when natural target-language delivery matters most, while cloning or original-sounding output makes more sense when speaker identity is central to the content. That is one of the most useful practical distinctions in the product.
- Treat human review as part of the workflow for high-stakes content. Speechlab’s own enterprise content repeatedly says AI dubbing works best with a tiered review model, especially for culturally sensitive, regulated, or brand-critical material. The platform looks built to accommodate that, not to eliminate it.
- If you need both subtitles and dubbed audio, try to keep them in one translation workflow rather than building them separately. That is one of Speechlab’s most convincing product arguments, and it is exactly the kind of process improvement that can save time later.
- The biggest trade-off is that Speechlab is not a lightweight consumer tool. Its strongest public pitch is around enterprise-scale dubbing, collaboration, integrations, bulk processing, and review workflows. That is great if you actually need those things. It is less compelling if you only want a simple creator-friendly dubbing app with minimal setup.
- The second trade-off is that the product’s best features depend on using the full workflow. Speechlab’s own blog makes it clear that good dubbing requires source separation, segmentation, transcript review, timing control, and decisions about whether to clone or match a speaker. In other words, the tool is not really promising one-click perfection. It is promising a better system for getting to production-ready output.
- The third trade-off is that some of the most important quality claims are still vendor claims. Speechlab’s public materials are thoughtful and fairly detailed, but they are still the company’s own description of its strengths. That means buyers should validate the platform on their own content, especially around speaker-heavy media, background-music handling, and target-language quality.
- And finally, Speechlab’s public product story is a little more enterprise-oriented than self-serve. The homepage clearly advertises free access for parts of the platform, but APIs, human-review layers, bulk workflows, and some collaboration features are framed around enterprise use rather than fully exposed self-serve documentation.
Speechlab looks strongest as a serious dubbing and live interpretation platform for teams that need more than just AI voices. Its best qualities are the integrated dubbing workflow, meaning-based editing model, subtitle-and-dub alignment, flexible speaker strategy, live interpretation layer, and enterprise-grade collaboration and review posture.
It is best for publishers, media teams, educators, enterprise marketing groups, and organizations localizing existing content at scale. The main caveat is that Speechlab is most valuable when you use it as a workflow system, not as a one-click voice generator.
TAGS: Translation Text to Speech
Related Tools:

Converts texts to podcasts

Word processing tool for creating and editing documents

Converts text into natural-sounding voiceovers
Translates text and speech between languages

Open-source office suite for document creation

Generates audio content from spoken words